Consider the simple web program. For the sake of convenience, we will assume it is written in Java. In its simplicity it most likely is as the following:
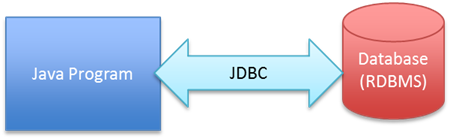
What are the implicit assumptions we are making?
- The database is supporting the reads and writes into the system.
- If other systems need this information, they access it from the database.
- Any writes happen directly to the database.
- The data fits in the database – both structure wise and size wise.
Now, let us see what the issues with these assumptions are. Turns out that we can relax or change each of these constraints to get a different kind of system. For now, let us take a specific path so that I can illustrate a point. I will cover the rest of the roads in other posts.
So, consider the case of database not being very convenient for access. That is, structurally, the data, while it fits well in the RDBMS (as relational tables), needs to be viewed in other forms, most notably as objects. And, of course, going to database for each and every access is costly.
Putting it another way, you need to have object interface to the database to handle the data well.
Enter ORMs (Object Relational Mappers). A typical layout would be:

What does this mean?
- The Java applications handle the data through POJO’s (plain old java objects).
- The ORM translates between the POJO’s and the relational tables of the RDBMs, using JDBC for communication.
Some popular choices for ORM are hibernate and OpenJPA.
It all looks hunky dory, until you start seeing performance hit. You realize that for a simple object look up, you end up doing a bunch of queries. Of course, you want to do some caching to take care of this problem. Now, the picture looks like this:

Summary: ORM could benefit from a cache.
Now let us look into this cache a little bit more deeply. If all that we are looking to speeding up the ORM, then we are fine with handcrafting a cache solution. Turns out that there are a lot of choices for Cache, as caching is a general-purpose paradigm.
Some popular choices for Cache include Ehcache etc.
Now, an interesting phenomenon is this: instead of cache, we can even use a main-memory database! After all, it is tuned to be in main-memory, with fast accesses and well debugged.
If we have a main memory database as a cache, the picture would look like this:

Now, look at how it looks: You have a main-memory DB and you have an RDBMS. You have your ORM synching between them, a job that it never signed up for. In fact, if you have main memory, can you get away with eliminating ORM completely, rendering the following picture?

Of course, it is possible only if the following hold:
- The main memory database should support all the data structurally.
- The main memory db should support all the data size wise as well.
- The synching from MMDM and RDBMs should be possible.
- If MMDB, in conjunction with the RDBMs should support transactions (ACID properties and perhaps roll backs).
- The Java program should be able to access MMDB fitting with the way Java programming is done.
Let us look at each of these areas and see how the picture changes:
MMDM and data structures
The standard RDBMs support only tables. If you want represent a matrix or a sparse array, you know the length of troubles you have to go through to represent in RDBMs. So, before you think, RDBMs are structurally superior, you should pause and think about that.
Enough dissing of RDBMs. Is there a way that MMDB’s operate to support different structures? There is good news and bad news. Perhaps bad news is good news.
The bad news is this: There is no one ubiquitous way that all the MMDB’s represent the data. That means, you cannot assume that the data is going to be in tables, neatly described by metadata. The side effect is that no way you can standardize the access to the MMDB. After all, you are storing different structures.
The good news, as a corollary is this: You can pick and choose the DB that is most suited for your purpose. That means, your program’s view of data and your MMDB’s view of data does not differ. That is a good state to be in.
There are a few choices that MMDB’s offer. Without being comprehensive, let me give you a couple of choices.
Key, value databases

In here, you can assume the whole database to be a giant table. (Think BigTable – in fact, google’s BigTable is a good example). Just like you access a hash table, you access your data in your MMDB.
A few things to observe:
- You can store anything that you want to in the KV store. In this picture, I showed storing as strings – but you can use other than the strings, say XML or Object serialization.
- You can retrieve only based on the key.
- It is not a general-purpose database – you cannot do general-purpose queries. The storage types are quite primitive.
There are several examples of this kind of databases: MemCache, Redis, and so on.
Document style databases:
One of the problems of KV style store is the opaqueness of the values. That is, the value is treated as just a value – you cannot peer into it, query it, see it as a complex structure. Document style db’s address that problem.
Let me illustrate it in the context of Mongo db, which is a document style:

Key points to note are:
- You are using very structured way of storing data. In fact, you are using JSON to store the data, which is nice to use.
- You don’t have a fixed schema. You can keep any data associated with the object.
- I did not show you the queries – you will see that you can query based on just about any column.
This kind of data storing is amazingly simple. Consider the alternative of storing in a relational database. You will store either metadata in the database or you will create a large schema. Either one will have problems. [This topic deserves a note of its own – someday.]
If you notice we are conflating two issues:
- Performance that comes from keeping the data in main memory.
- Supporting the right kind of data structures in the database.
For example, we can even support relational data in main memory. A properly tuned Oracle keeps lot of table data pinned in the memory.
So, for our needs, we can think of the structure of the data is primary.
Distributing data: key to scalability
So far, we have been assuming that all the data resides in memory. What if the data doesn’t fit in the memory (of one machine)? For instance, JVM has well known limitations on the memory (on 32bit machines, it can support, at best 4GB, and in reality considerably less; on 64bit machines with 64bit JVM, too many issues to maximize the heap), we may want to keep the database out of the JVM process.
There are other reasons why you want to keep outside the process as well. For instance, what if you want to use the same db from multiple apps? What if we want to independently backup and synchronize the database?
The best way to do that would be:

That is, you partition the data and go to different data source (node) for querying. The mapper determines where to go for which data – think of it as a hash function.
For example, let us say all the customer information is partitioned based on the first letter of their name. You don’t need a mapper explicitly – each application can map the query to the node and get the information via a web service or something equally simple.
Of course, with this kind of partitioning a few questions will come up:
- What is the effective way of partitioning the data? (think: There are not that many people whose name starts with Q).
- How do we create partition tolerance? What if one of the nodes goes down? Can we have a different node answer the same query? If we have a different server, how does that synchronize with the original one?
- How do we support transactions? Can we support Atomicity? Concurrency? Isolation? Durability?
Turns out that there is a theorem (CAP theorem) that shows that you can’t have everything: consistency of the data across all the nodes, availability of the data even if some nodes may fail, and partition tolerance (failure in syncing the data between nodes will not cause problems for the systems, in the short term). The real theorem is more complex – read it up if you want to really know what it says.
So, what do people do? Actually, the compromise in the quality of the database supports interesting real-life situations. For example, let us say that you uploaded a photo from your home and your friend in India doesn’t see if for 2 minutes. Would you be upset? Or, you commented on some thread and somebody else doesn’t see it for a while. Or, your bulletin board doesn’t respond occasionally throwing open a page saying “Please visit in a little while”?
All of these are examples of specific situations that even with limitations of CAP, can be addressed usefully with these kind of databases.
What is the lesson for us?
Here is what we have seen so far:
For some specific situations, NoSQL databases can offer simpler mode of development and higher performance for web development.
If you are developing some expertise for yourself or your group, these are the areas that could help:
-
Understand and classify the situations for which NoSQL databases work well. Create a flow chart for choosing the right technology components suitable for the problem context.
-
Most enterprises are nervous about the risk – which NoSQL DB is going to survive? They recall the days of betting on Sybase only to ask for migration funding years later. So, create a risk mitigation strategy:
- By creating an API layer that is more semantic in nature and is implemented on more than one NoSQL db.
- By creating a way of syncing the data with the backend Oracle or DB2.
-
Tune the performance by adjusting the level of C or A or P that we need. In fact, you will find out different databases support different CAP. This knowledge is useful to recommend and tune a NoSQL database for a specific need.
In the later posts, I will drill down into these topics to see how we can put together the right solutions for the problems that we face.