“Until you can measure something and express it in numbers, you have only the beginning of understanding.” – Lord Kelvin.
There are lot of things we want to measure, even if they can’t be objectively measured. For example, we measure customers satisfaction – there are no scientific units to use for the measurement. We measure popularity with proxy metrics like number of Google hits. Measuring anything objectively is itself a challenge.
My first company, Savera Systems Incorporated, had stellar advisers. One of them, Jeff Ullman told us the following: “Whatever you measure, you improve that metric”. I observed that to be correct. It is our tendency to improve whatever we measure. But, it is not the complete story.

Let us say your CEO laid out the vision for the company: “becoming a leader in the online sales of hair tonic”. The goal could be “increase the sales by 100% in North America”. Now that we measure the sales, do they automatically increase? Unfortunately no.
There were a series of tests conducted by education psychologists in 2005. In some cases, they paid students money for getting good grades. In some cases, instead of grades, they measured the number of days absent, number of assignments turned in, number of books read etc. What they realized was that there was no effect on the grades when they paid for the grades. But, there was positive correlation when they paid for attending classes and reading books.

When we measure people on what they control , that has a positive impact. When we measure on what they can’t control, there was no impact. Attending classes is something that the students controlled; getting grades was not something they controlled. So, we convert what we want to measure to proxy metrics.
So, let us say that we measure what they can control using these proxy metrics. Surely that helps our cause, right?
In the last few years, we realized that measuring the company performance without regarding the constraints (legal and ethical) had lead to long term damage to the companies and the world. Suppose we pay students for grades, what prevents them from cheating? Unless we impose the constraints, the metrics will become meaningless.
Let us say that we impose the proper constraints, will it be sufficient? Again, no. The problem is that sometimes by the time we got the measurements, it is already late. For example, let us say that we are measuring the sales performance to increase the revenue. By the time we measure the performance, we lose the ability to control the outcome. There is no chance for course correction.
So, what we do is to measure the leading indicators. These indicators portend what is going to come. For example, building permits for new construction is a leading indicator for the economy. In contrast, average prime rate is a lagging indicator. The indicators that move with the main metric are called coincident indicators, which we don’t have to bother about now.
The issue with leading indicators is that they are not always good indicators. They are often not well-defined; their correlation with the main indicator is not well-understood; there is a chance that the correlation could vary. Still, with all uncertainty, leading indicators offer better chance of reaching our goals than coincidental indicators.
We are not done yet. Suppose we are measuring the school performance by attendance. The principal incentivizes the students for attending school. Then, even the people who are not interested in school attend it. In fact, it may be possible that they disrupt the school so much that the school performance may go down.
Or, consider the case of paying for the number of bugs fixed. This payment may lead to perverse incentive for introducing trivial bugs or even breaking down a large bug as several sub-bugs. In fact, it is fairly common in medical industry to break down a single problem as a series of several ailments, each of which is separately treated and billed. What we are seeing is "unintended consequence" of a good intention.
That leads us to selection of several metrics that covers the desired outcome. These metrics collectively support the desired outcome without leading to unintended consequences. Since there can be many such metrics, we can stipulate the following rules:
- The metrics should be independent: Think of as vectors which are orthogonal. Otherwise, these metrics end up duplicating the effect. This is easy enough to validate, either empirically or even sometimes through modeling the problem.
- The metrics should be few in number: If we measure too many, the complexity of measuring overwhelms the people to understand what is being measured. This is often the cause for people not showing enthusiasm for metrics.
- The metrics should cover the original desired outcome: How can we be sure that we got all the metrics covered? That is a difficult problem to solve. It is more of a craft than science. I suppose we can choose large enough number of metrics, but that messes up the earlier rule of having few metrics.
Note for enterprise architects
When enterprise architects plan the IT activities for an organization, they create a strategy, a plan to realize the strategy, and a program to execute the plan. Unless they create the metrics at every stage they will not have traceability for the entire program.
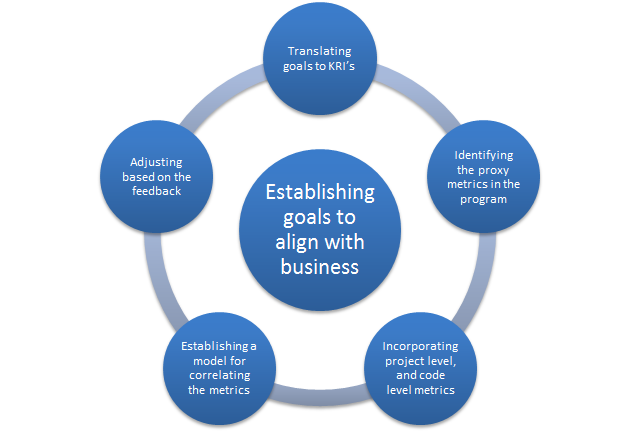
There are several artifacts that we use in this process:
- A model to translate the metrics from one stage to another.
- A correlation mechanism to establish the relationship from one stage metrics to another.
Without going into full details, here are some tips for this methodology:
- Goals to KRI (Key Result Indicator)’s: While the organization goals can be nebulous, KRI’s have to be precise. They need to establish what we are measuring, how we are measuring, and who the people are that are responsible for those KRI’s are.
- KRI’s to program metrics: While KRI’s are precise to measure, they tend to be lagging or coincidental indicators. What we need are leading indicators. At a program level, we can establish leading indicators, simply by identifying the indicators that we can measure while the program is in progress. For instance, when we construct a program, we typically break down the program into multiple, simultaneous projects. By establishing the metrics that can be measured throughout the life cycle, we are creating the simplest leading indicators.
- Establishing code level metrics: Eventually, we should focus on automated creation of metrics. By incorporating into code, we ease the process. For instance, if we are trying to improve customer satisfaction, we might measure the number of interactions that a customer had to have to resolve the issue. Or, the duration of the open issue. Or, number of exceptions that service reps had to take. Of course, the earlier part of the essay described the process of choosing the metrics: for completeness, independence, and with constraints.
- Establishing the feedback loop: As long as a we have a model that correlates the events at each stage, we can keep refining based on the information from the ground. The idea is that we end up with manageable number of metrics that can predict the final outcome reliably.
I have not found a good book on this subject that provides a good mixture of management processes, Enterprise architecture processes, mathematical models, and behavioral psychology. I wrote this piece entirely from my experience. If anybody knows some good resources on this topic, please inform me via the comments.