There is a lot of interest in moving applications to the cloud. Considering that there is no unanimous definition of cloud, most people do not understand the right approach to migrate to the cloud. In addition, the concept of migration itself is complex; what constitutes an application is also not easy to define.
There are different ways to interpret cloud. You could have private or public cloud. You could have just data center for hire or a full-fledged, highly stylized platform. You could have managed servers or instead measure in terms of computing units, without seeing any servers.
As we move applications to any of these different kinds of clouds, you will see different choices in the way we move the applications.
Moving a simple application
Let us consider a simple application.
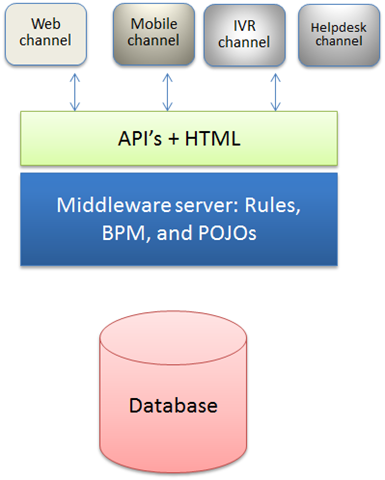
The application is straightforward. Two or three machines run different pieces of software and produce a web-based experience to the customers. Now, how does this application translate to the cloud?
As-is to as is moving
Technically, we can move the machines as-is to a new data center, which is what most people do with the cloud. The notable points are:
- To move to “cloud” (in this case, just another data center), we may have to virtualize the individual servers. Yes, we can potentially run whatever OS on whatever hardware, but most cloud companies do not agree. So, you are stuck with X64 and possibly, Linux, Windows, and a few other X64 OS’s (FreeBSD, illumos, smartOS and also variants of Linux).
- To move to cloud, we may need to setup the network appropriately. Only the web server needs to be exposed, unlike the other two servers. Additionally, all three machines should be in LAN for high bandwidth communication.
- While all the machines may have to be virtualized, database machine is something special. Several data bases, Oracle included, do not support virtualization. Sure, they will run fine in VM’s, but the performance may suffer a bit.
- In addition, databases have built-in virtualization. They support multiple users, multiple databases, with (limited) guarantees of individual performances. A cloud provider may offer “database as a service” which we are not using now.
In summary, we can move applications as-is to as-is, but we still may have to move to X64 platform. Other than that, there are no major risks associated with this move. The big question is, “what are the benefits of such a move?” The answer is not always clear. It could be a strategic move; it could be justified by the collective move of several other apps. Or, it could be the right time before making the investment commitment to the data center.
Unfortunately, moving applications is not as easy. Consider the slightly more complex version of the same application:
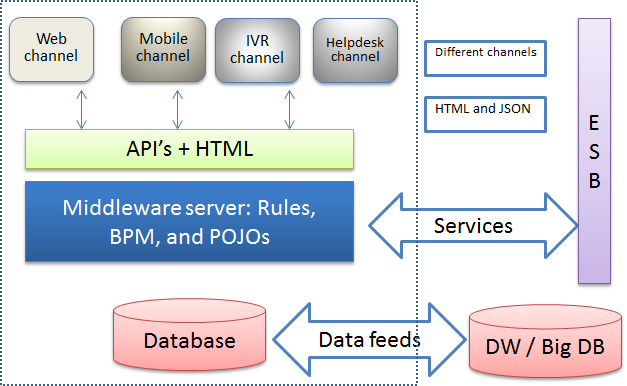
Let us say that we are only moving the systems within the dotted lines. How do we do it? We will discuss those complexities later, once we understand how we can enhance the moving that treats cloud like a true cloud.
Migration to use the cloud services
Most cloud providers offer many services beyond infrastructure. Many of these services can be used without regard to the application itself. By incorporating into the processes and also adding new processes to support the cloud can improve the business case to moving to the cloud. For instance, these services include:
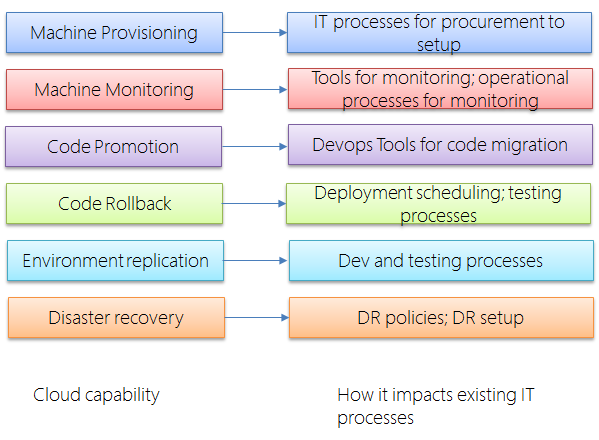
Changes to these processes and tooling is not specific to one application. However, without changing these processes and ways of working, the cloud will remain yet another data center for the IT.
Migration to support auto scaling, monitoring
If we go one step ahead, by adjusting the non-functional aspects of the applications, we can get more out of the cloud. The advantage of the cloud is the ability to handle the elasticity of the demand. In addition, paying for only what we need is very attractive for most businesses. It is a welcome relief for architects who are asked to capacity planning based on dubious business plans. It is even bigger relief to infrastructure planners who chafe at the vague capacity requirements from architects. It is much bigger relief for the finance people who need to shell out for fudge factor built into capacity by the infrastructure architects.
But, all of that can work well only if we make some adjustments in the application architecture, specifically the deployment architecture.
How does scaling happen? In vertical scaling, just move to bigger machine.
The problem with this approach is the cost of the machine goes up dramatically as we scale up. Moreover, there is a natural limit to the size of the machine. If you want to have disaster recovery, you need to add one more of the same size. And, with upgrades, failures, and other kind of events, large machines do not work out economically.
Historically, that was not the case. Architects preferred scaling up as it was the easiest option. Investments into hardware went towards scaling up the machines. Still, with new internet companies, they could not scale vertically; the machines weren’t big enough. Once they figured out how to scale horizontally, why not use the most cost effective machines? Besides, a system might require the right combination of storage, memory, and compute capacity. With big machines, it wasn’t possible to tailor to the exact specs.
Thanks to VMs, we could tailor the machine capacity to the exact specs. And with cheaper machines, we could create the right kind of horizontal scaling.
However, horizontal scaling is not so easy to achieve. Suppose you are doing a large computation – say, factorization of large number. How do you do it on multiple machines? Or, if you are searching for an optimal path though all the fifty state capitals? Not so easy.
Still, several problems are easy to scale horizontally. For instance, if you are searching for records through large set of files, you could do the searching on multiple machines. Or, if you are serving web pages, different users can be served from different machines.
Considering that most applications are web based apps, they should be easy to scale. In the beginning, scaling was easy. None of the machines shared any state – that is, there is no communication among the machines was required. However, once J2EE marketing machine moved in, these application servers ended up sharing state. There are other benefits, of course. For instance, if a machine goes down, the user can be seamlessly served out of another machine.
Suppose you introduce a machine or take out a machine. The system should be adjusted so that session replication can continue to happen. What if we run one thousand machines? Would the communication work well enough? In theory it all works, but in practice it is not worth the trouble.
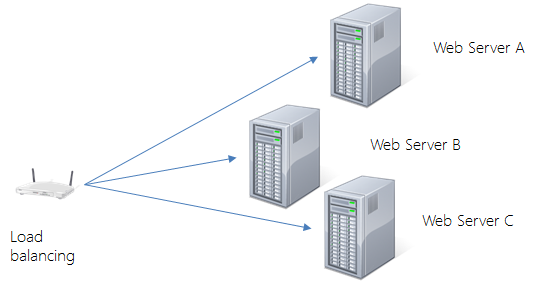
Scaling to large number of regular machines works well with stateless protocols, which are quite popular with the web world. If any existing system does not support this kind of architecture, it is not difficult to adjust to this architecture without wholesale surgery on the application.
Most data centers do monitoring well enough. However, in cloud, monitoring is geared towards maintenance of large number of servers; there is a greater automation built in; there is lot more log file driven automation. Most cloud operators provide their own monitoring tools instead of implementing the customer’s choice of monitoring tools. In most cases, by integrating into their tools (for instance, log file integration, events integration), we can reduce the operational costs of the cloud.
Migration to support cloud services
If you have done all that I told you to – virtualize, move to cloud, use auto- scaling, use the monitoring, what is left to implement? Plenty, as it turns out.
Most cloud providers provide lot of common services. Typically, these services operate better on scale. And, they also implement well-defined protocols or needs. For instance, AWS (Amazon Web Services) offers the following:
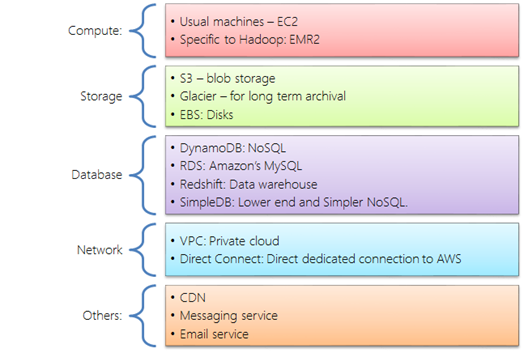
Given this many services, if we just go from machines to machines, we might just use EC2 and EBS. Using these services not only saves money and time, but eventually, ability to use trained engineers and third party tools.
Re-architecting a system using these services is a tough task. In my experience, the following order provides the best bang for the buck.

The actual process of taking an existing application and moving it to this kind of infrastructure is something that we will address in another article.
Re-architecting for the cloud
While there may not be the right justification for re-architecting the applications entirely, for some kind of applications, it makes sense to use the platform that the cloud providers offer. For instance, Google compute offers a seductive platform that offers the right kind of application development. Take a case of providing API for product information that your partners are embedding on their site. Since you do not know what kind of promotions your partners are running, you have no way of even guessing how much the traffic is going to be. In fact, you may need to scale really quickly.
{kind=link}
If you are using say, Google app engine, you won’t even be aware of the machines or databases. You would use an appengine, and the APIs for big table. Or, if you are using any platforms provided by the vendors (Facebook, SFDC, etc.), you will not think of machines. Your costs will truly scale up or down without actively planning for it.
However, these platforms are suitable for only a certain kind of application patterns. For instance, if you are developing a heavy duty data transformation, a standard appengine is not appropriate.
Creating an application for a specific cloud or platform would require designing the application to make use the platform from the cloud. By also providing standard language runtime, libraries, services, the platform can lower the cost of development, I will describe the standard cloud based architectures and application patterns some other day.
Complexities in moving
Most of the complexities come from the boundaries of applications. You saw how many different ways the application can be migrated if self-defined. Now, what if there are lot of dependencies? Or, communication between applications?
Moving in groups
All things being equal, it is best to move all the applications at once. Yet, for various reasons we move only few apps at a time.
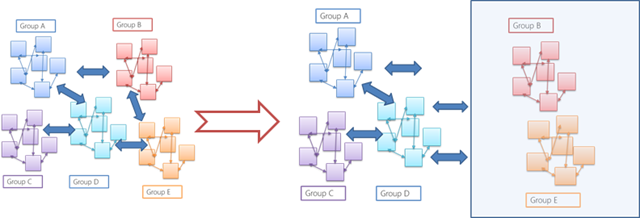
If we are migrating applications in groups, we have to worry about the density of dependencies, the communications among the applications. Broadly speaking, communication between apps can happen the following ways.
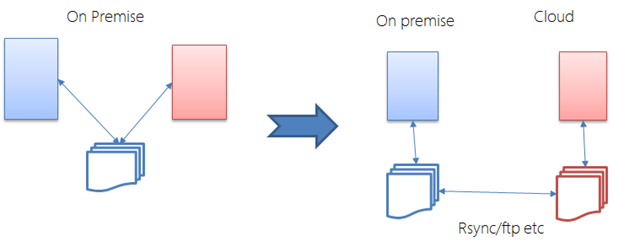
Exchange of data via files
Many applications operate on import and export (and transformation jobs in between). Even when we move a set of applications, it is easy enough to do these file based communication. Since file-based communication is typically asynchronous, it is easy to setup for the cloud.
Exchange of data via TCP/IP based protocols
In some cases, applications may be communicating via standard network protocols. Two applications may be communicating via XML over HTTP. Or, they could be communicating over standard TCP/IP with other kinds of protocols. X windows applications communicate over TCP/IP with X server. Applications can use old RPC protocols. While these protocols are not common anymore, we might encounter these kind of communications among applications.
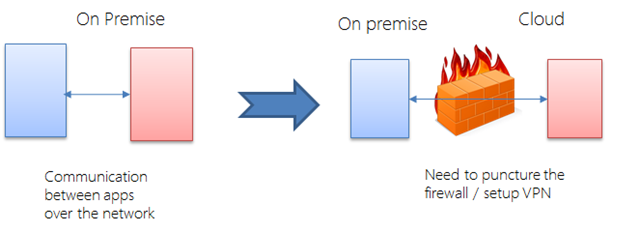
To allow the communication to continue, we need to setup the firewall to allow such communications. Since we know the IP numbers of end points, specific ports, and specific protocols, we may be able to setup effective firewall rules to allow such communication. Or we can set up VPN between the two different locations.
It is easy to handle the network throughput; in most applications, the throughput requirements are not very high. However, it is very common to have a low latency requirement between applications. In such cases, we can consider dedicated network connection between the on-premise center and the cloud data center. In several ways, it is similar to handling multi-location data centers.
Even with a dedicated line setup, we may not be fully out of woods yet. We may still need to reduce the latency further. In some cases, we can deal with it by caching and other similar techniques. Or, better yet, we can migrate to modern integration patterns such as SOA or message bus using middleware.
Exchange of data via messages or middleware
If we are using middle ware to communicate, the problem becomes simpler. Sure, we still need to communicate between the apps, but all the communications go through the middleware. Moreover, middleware vendors are dealing with integrating applications across continents, across different data centers, and across companies.
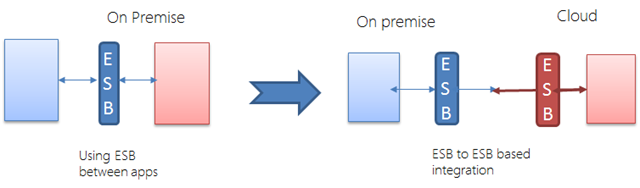
ESB or any other variants of middleware can handle a lot of integration- related complexities. They can do transformation, caching, store and forward, and security. In fact, some of the modern integration systems are specifically targeted towards integrating with the cloud, or running integration systems in the cloud. Most cloud providers offer their own messaging systems that work not only within their clouds, but also across the Internet.
Database based communication
Now, what if applications communicate via database? For instance, an order processing system and an e-commerce system communicating via database. And, if e-commerce system is on the cloud, how does it communicate with on-the-premise system?
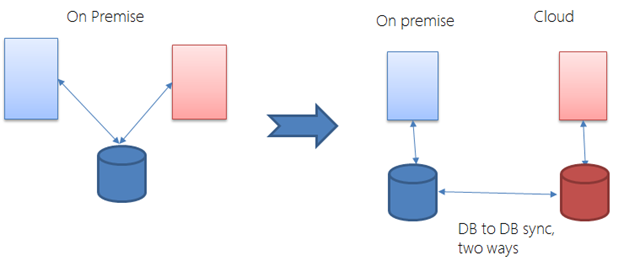
DB-to-DB sync has several special tools, since this is a common problem. If the application doesn’t require a real-time integration, it is easy to sync the databases. Real-time or near-real-time integration between databases requires special (and often expensive) tools. A better way is to handle the issue at the application level. That means we should plan for asynchronous integration.
Conclusion
Moving applications to cloud opens up many choices, each choice with its own costs and benefits. If we do not understand the choices and treat every kind of move as equal, we risk not getting the right kind of ROI from moving to cloud. In another post, we will discuss the cloud migration framework and how to create the business case, and also how to understand what application should migrate to which cloud and to what target state.